











Building a robust online store requires more than just a frontend interface. The backbone of any successful digital marketplace lies in its data architecture. An Entity Relationship Diagram (ERD) serves as the blueprint for how information is stored, related, and retrieved. When designing for scale, the complexity increases significantly. You must balance data integrity with performance, ensuring that every transaction processes smoothly even under heavy load.
This guide explores the critical components of e-commerce database design. We will examine the core entities, their relationships, and the patterns necessary to support high-volume traffic. By following these structural principles, you can build a system that remains stable as your customer base grows. The focus is on logical design, normalization, and strategies that prevent bottlenecks before they occur.
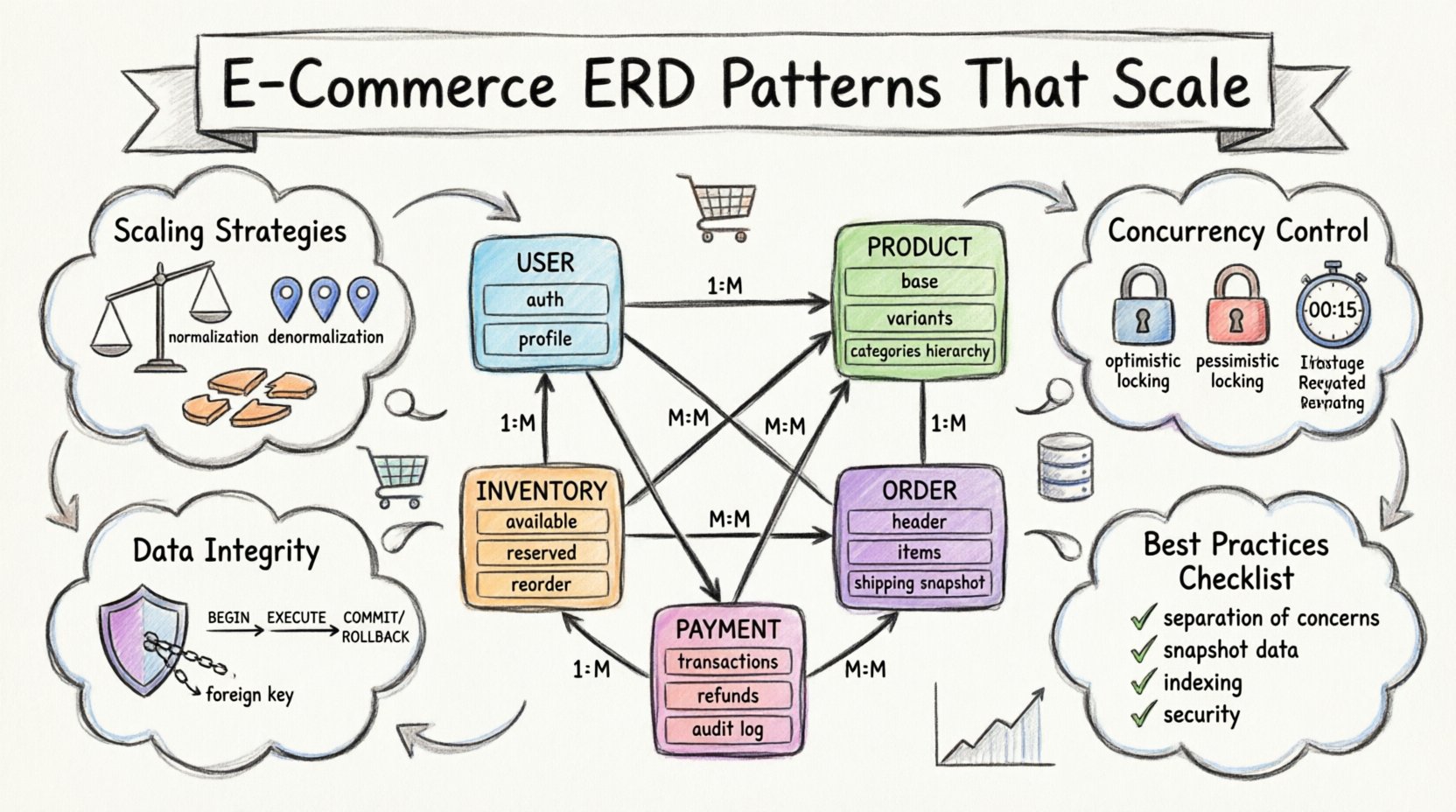
Foundational Entities and Core Relationships 🏗️
Every e-commerce platform begins with the fundamental data points that define the business. These include who the customers are, what they buy, and how items are categorized. The design of these core tables dictates the flexibility of the entire system.
1. The User Entity
The user table is the entry point for authentication and profile management. However, separating authentication credentials from user profile details is a common pattern. This separation allows for security updates without disrupting the broader user data structure.
- Authentication Data: Stores credentials, session tokens, and account status. This data requires high security and minimal exposure.
- Profile Data: Contains names, contact information, and shipping preferences. This data is more frequently updated.
- Relationships: A one-to-many relationship exists between users and their order history. Each user can have multiple orders, but an order belongs to exactly one user.
It is important to consider privacy regulations at this stage. Storing personally identifiable information (PII) requires specific handling. Encryption at rest and strict access controls are standard practices for this entity.
2. The Product Catalog
Product management is often the most complex part of an e-commerce schema. A single physical item might exist in multiple variations, such as size or color. This necessitates a flexible structure that does not require constant schema changes.
- Product Base Table: Holds general information like title, description, and base price.
- Variant Table: Stores specific attributes like SKU, color, size, and individual pricing.
- Category Table: Defines the hierarchy. Categories can be nested, requiring a self-referencing relationship or a path enumeration strategy.
Denormalization is often considered here. While normalization reduces redundancy, reading data for a product listing page requires joining multiple tables. In high-traffic scenarios, caching the joined data or denormalizing specific fields can improve query speed.
3. Inventory and Stock Management
Tracking stock levels is critical to prevent overselling. The inventory table must link directly to product variants. It should store the current available quantity, the reserved quantity, and the total capacity.
- Available Stock: The number of items ready for immediate purchase.
- Reserved Stock: Items held in a customer’s cart during checkout.
- Reorder Point: A threshold that triggers alerts for restocking.
Concurrency is a major challenge here. If two users attempt to buy the last item simultaneously, the system must prevent both from succeeding. This usually involves database transactions that lock the specific inventory row during the update process.
Transactional Architecture and Order Processing 🛒
The order lifecycle is the heartbeat of the platform. It represents the movement of value from the customer to the merchant. The database design must support the state changes that occur from cart to fulfillment.
Order Entity Structure
An order record is a snapshot of the transaction at a specific point in time. It should not simply reference the current product price. If the price changes after the order is placed, the historical record must remain accurate.
- Order Header: Contains the order ID, user ID, total amount, tax, shipping cost, and order status.
- Order Items: A junction table linking orders to products. This table records the specific variant, quantity, and price at the time of purchase.
- Shipping Address: Storing the address at the time of order is safer than linking to the user’s current address profile.
Status Management
Orders move through various states. A well-designed status field allows the system to track progress without requiring complex joins. Common statuses include:
- Pending: Order created but not yet paid.
- Paid: Payment confirmed.
- Processing: Inventory allocated and being prepared.
- Shipped: Item dispatched with tracking information.
- Delivered: Customer received the item.
- Refunded: Money returned to the customer.
Using an enumerated type for status ensures data consistency. It prevents typos that could break automation scripts relying on specific status values.
Payment and Financial Records 💳
Financial data requires the highest level of accuracy. You cannot rely on standard application logic alone for money. The database must record the financial transaction as a distinct event.
- Payment Transactions: Each payment attempt should create a record. This includes the gateway response, the method used, and the final result.
- Refunds: A refund is a separate transaction linked to the original payment. It should not simply zero out the original record.
- Tax Calculations: Tax rates vary by location. Storing the applied tax amount per order item ensures auditability.
Audit logging is essential here. Every change to a financial record should be logged with a timestamp and the user ID performing the action. This provides a trail for dispute resolution and internal auditing.
Scaling Strategies for High Volume 📈
As traffic grows, the database becomes a bottleneck. Standard scaling involves vertical scaling (adding more power to a single server), but this has limits. Horizontal scaling (adding more servers) requires careful data distribution planning.
1. Normalization vs. Denormalization
Normalization reduces data duplication. It is the standard for transactional integrity. However, complex queries that join many tables can become slow as the data volume increases.
| Strategy | Benefit | Drawback |
|---|---|---|
| Normalization | Data consistency, less storage | Complex queries, slower reads |
| Denormalization | Faster reads, simpler queries | Data redundancy, update complexity |
In e-commerce, a hybrid approach is often best. Keep the core transactional tables normalized to ensure integrity. Create denormalized views or separate tables for reporting and search purposes. This allows fast product browsing without compromising the accuracy of order processing.
2. Indexing Strategies
Indexes are crucial for performance. They allow the database to find rows without scanning the entire table. However, too many indexes slow down write operations.
- Primary Keys: Always indexed. Used for direct lookups by ID.
- Foreign Keys: Often indexed to speed up joins between related tables.
- Composite Indexes: Useful for queries that filter by multiple columns, such as status and date.
- Full-Text Indexes: Essential for product search functionality.
Review query execution plans regularly. If a query is not using an index, the database may be performing a full table scan, which degrades performance as the dataset grows.
3. Partitioning and Sharding
When a single table becomes too large, partitioning splits it into smaller, manageable pieces. This is often done by date or by ID range.
- Range Partitioning: Splitting orders by year or month. This keeps recent data on faster storage while archiving old data.
- Hash Partitioning: Distributing data across multiple servers based on a hash of the ID. This spreads the load evenly.
Sharding takes this further by distributing data across multiple physical servers. This requires the application to know which shard contains the data. It is a complex architectural decision best implemented after vertical scaling is exhausted.
Data Integrity and Constraints 🔒
Relational databases offer powerful constraints to maintain data quality. Relying on application code to enforce rules is risky, as code can have bugs. Database constraints provide a safety net.
1. Referential Integrity
Foreign key constraints ensure that an order always links to a valid user and product. If a product is deleted, the database can be configured to either prevent the deletion or cascade the action to dependent records. In e-commerce, preventing deletion of products with existing orders is usually the safer choice.
2. Transactional Atomicity
A transaction groups multiple operations into a single unit. Either all operations succeed, or none do. This is vital for inventory updates. When an order is placed, the inventory must decrease. If the inventory update fails, the order record should not be created.
- Begin Transaction: Locks the relevant resources.
- Execute Updates: Perform the necessary writes.
- Commit: Makes the changes permanent.
- Rollback: Reverts changes if an error occurs.
3. Unique Constraints
Unique constraints prevent duplicate entries. This is useful for email addresses in the user table or SKU codes in the product table. It prevents the system from accidentally creating duplicate accounts or conflicting inventory items.
Handling High Concurrency ⚡
Flash sales and high-traffic events create race conditions. Multiple users might try to purchase the same item at the exact same millisecond.
Optimistic Locking
Optimistic locking assumes conflicts are rare. It involves adding a version number to the row. When updating, the database checks if the version number matches. If it has changed, the update is rejected, and the application must retry.
Pessimistic Locking
Pessimistic locking locks the row immediately upon reading. Other transactions must wait until the lock is released. This guarantees data consistency but can reduce throughput during high contention.
Inventory Reservation
To prevent overselling, reserve inventory when the user adds an item to the cart. Set a timeout for this reservation. If the user does not complete the checkout within the time limit, the inventory is released back to the available pool.
Search and Analytics Considerations 📊
Transactional databases are not designed for complex analytical queries or full-text search. Running heavy search queries on the main order or product tables can degrade performance for regular users.
- Search Engines: Use a dedicated search engine for product discovery. Sync product data from the main database to the search engine asynchronously.
- Analytics Warehouses: Move historical data to a separate analytical store for reporting. This keeps the transactional database lightweight.
- Read Replicas: Direct read-only traffic to replica servers. This separates the load from the primary write server.
By separating write-heavy operations from read-heavy operations, you ensure that the checkout process remains fast even when users are browsing or generating reports.
Maintenance and Long-Term Growth 🔄
A database design is not static. It must evolve with the business. As new features are added, the schema may need adjustments.
- Versioning: Keep track of schema versions. This allows for safe rollbacks if a migration fails.
- Archiving: Move old orders to cold storage. This keeps the active table size manageable.
- Monitoring: Set up alerts for slow queries, lock waits, and disk space usage. Proactive monitoring prevents outages.
Regularly review the ERD against actual usage patterns. Some relationships that looked good on paper may prove inefficient in production. Be prepared to refactor when data patterns change significantly.
Summary of Best Practices ✅
Designing a scalable e-commerce database requires a balance of structure and flexibility. The following points summarize the key takeaways for building a resilient system.
- Separation of Concerns: Keep authentication, catalog, and transaction data distinct.
- Snapshot Data: Store order details at the time of purchase, not just references.
- Concurrency Control: Use transactions and locking to prevent overselling.
- Indexing: Optimize for the most common read and write patterns.
- Scalability: Plan for partitioning and sharding early in the architecture.
- Security: Encrypt sensitive data and enforce strict access controls.
By adhering to these patterns, you create a foundation that supports growth. The database becomes a stable engine that powers the business without requiring constant emergency fixes. Focus on data integrity first, then optimize for speed. A slow system is better than an incorrect one.