











Designing a robust database schema for social media platforms requires a deep understanding of how users interact, share, and consume information. Unlike traditional transactional systems, social networks involve complex many-to-many relationships, recursive data structures, and massive scale requirements. The Entity-Relationship Diagram (ERD) serves as the blueprint for these interactions, ensuring data integrity while supporting rapid growth. This guide explores the critical strategies for modeling social media data effectively.
Understanding the Core Challenge 🧩
Social media applications are not merely repositories of content; they are dynamic networks of relationships. A simple blog post differs significantly from a social media feed because of the engagement layer. Likes, shares, comments, and follows create a web of connections that must be modeled accurately. Poor modeling leads to slow query performance, data inconsistency, and difficulty in implementing features like news feeds or friend suggestions.
- Volume: Social platforms generate millions of events per second.
- Velocity: Data arrives in real-time streams that must be processed immediately.
- Variety: Content includes text, images, videos, metadata, and location data.
- Relationships: The core value lies in the connections between entities.
When constructing an ERD, the primary goal is to balance normalization with performance. Over-normalization can make joins too expensive for high-frequency reads. Over-denormalization can lead to data redundancy and consistency issues. The following sections detail the specific entities and relationships that define this domain.
Defining Core Entities 🔑
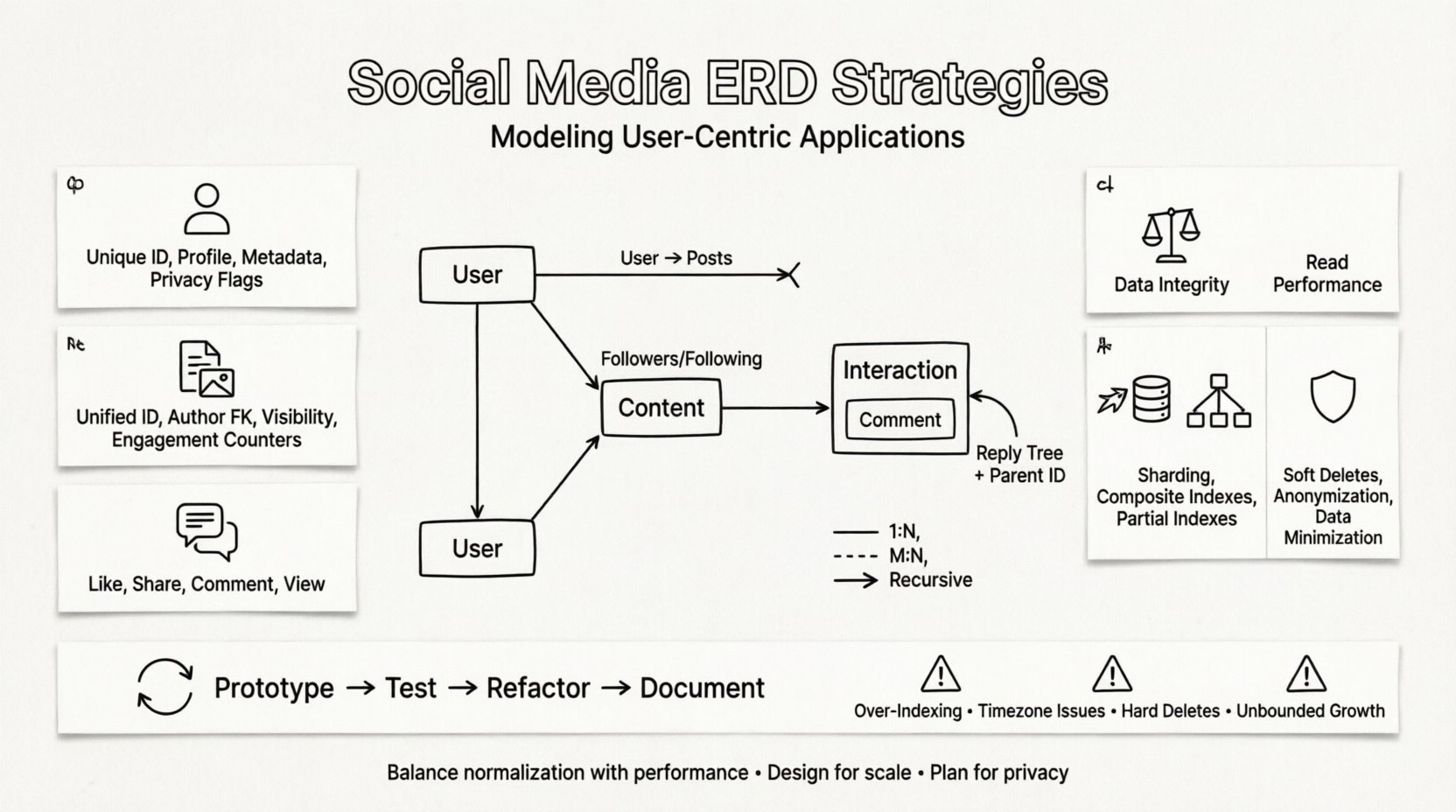
Every social media system revolves around a few fundamental entities. Identifying these correctly is the first step in creating a scalable schema. These entities represent the core building blocks of the application.
1. The User Entity 👤
The user is the central node in the network. This entity stores authentication details, profile information, and preferences. It must be designed to handle millions of records efficiently.
- Unique Identifier: A surrogate key is preferred over natural keys for performance and anonymity.
- Profile Data: Name, bio, avatar, and verification status.
- Metadata: Timestamps for account creation, last login, and deletion.
- Privacy Flags: Settings controlling visibility of data to other users.
2. The Content Entity 📝
Content is the fuel of social platforms. It encompasses posts, stories, images, videos, and comments. A flexible schema is required because different types of content have different attributes.
- Unified ID: A generic ID that links to specific content tables.
- Author Reference: A foreign key linking to the User entity.
- Visibility Scope: Public, private, friends-only, or specific groups.
- Engagement Counters: Cached counts for likes and comments to reduce query load.
3. The Interaction Entity 💬
Interactions represent the actions users take on content or other users. These are high-volume transactions that often dictate the performance requirements of the system.
- Like: A binary state between a user and content.
- Share: A reference to the original content with a new context.
- Comment: A hierarchical or threaded relationship to content.
- View: Often logged separately due to high volume and lower importance for integrity.
Modeling Relationships 🕸️
The true complexity of social media lies in the relationships between entities. Standard relational modeling techniques often struggle with the recursive nature of social graphs. Special attention must be paid to how these connections are stored.
One-to-Many Relationships
These are the most common and straightforward. For example, one user can have many posts, but a post belongs to only one user. This is modeled using a foreign key in the child table.
- Example: User ID in the Posts table.
- Benefit: Fast retrieval of all posts for a specific profile.
- Constraint: Enforces referential integrity automatically.
Many-to-Many Relationships
Followers and following are the classic example. One user follows many others, and one user is followed by many others. This requires a junction table to resolve the relationship.
- Junction Table: Contains User ID A and User ID B.
- Timestamps: When the follow action occurred.
- Status: Pending, accepted, or blocked.
- Performance: Indexing is critical on both foreign keys.
Recursive Relationships
Some relationships involve the same entity type. A comment can have replies to replies. This creates a tree structure that is difficult to query in standard relational models.
- Parent ID: A foreign key pointing to the Comment ID.
- Depth: Limiting recursion depth prevents infinite loops.
- Materialized Paths: Storing the path of the tree for faster traversal.
| Relationship Type | Example | Implementation Strategy | Performance Impact |
|---|---|---|---|
| One-to-Many | User – Posts | Foreign Key in Child | Low (Standard Indexing) |
| Many-to-Many | User – Follows | Junction Table | Medium (Join Overhead) |
| Recursive | Comment – Reply | Self-Referencing FK | High (Complex Queries) |
| Associative | Tag – User | Composite Keys | Medium (Lookup Heavy) |
Normalization vs. Denormalization ⚖️
In social media systems, read performance often outweighs write performance. Users expect feeds to load instantly, even when millions of records are involved. This necessitates a careful balance between normalization and denormalization.
The Case for Normalization
Normalization ensures data integrity and reduces redundancy. It is essential for core data that does not change frequently.
- Data Consistency: Updates happen in one place.
- Storage Efficiency: Less duplicate data storage.
- Maintainability: Easier to enforce business rules.
The Case for Denormalization
Denormalization involves duplicating data to reduce the number of joins required during reads. This is common in social feeds.
- Read Speed: Fewer joins mean faster query execution.
- Caching: Aggregated counts (e.g., total likes) stored directly.
- Write Overhead: Updates must be propagated to all copies.
Hybrid Approach
A practical strategy involves normalizing the core schema while denormalizing frequently read metrics. For example, store the user name in the post table alongside the user ID. This avoids a join when displaying the post, at the cost of occasional synchronization logic.
Scalability Strategies for ERDs 🚀
As the user base grows, the schema must evolve to handle increased load. Vertical scaling has limits; horizontal scaling requires specific schema considerations.
Partitioning
Partitioning splits large tables into smaller, manageable pieces. In social media, data is often partitioned by user ID or date.
- Horizontal Partitioning: Splitting users across different shards based on ID ranges.
- Vertical Partitioning: Moving infrequently accessed columns to a separate table.
- Date Partitioning: Archiving old posts to cold storage tables.
Indexing Strategies
Indexes are vital for query performance, but they slow down writes. A strategic approach to indexing is required.
- Composite Indexes: Covering common query patterns (e.g., User ID + Timestamp).
- Partial Indexes: Indexing only relevant rows (e.g., active posts).
- Search Indexes: Using full-text search engines for content discovery.
Privacy and Compliance Considerations 🛡️
Modern data modeling must account for privacy regulations like GDPR and CCPA. The schema design impacts how easily data can be anonymized or deleted.
Right to be Forgotten
Users can request the deletion of their data. The ERD must support cascading deletes or soft deletes without breaking referential integrity.
- Soft Deletes: Adding an “is_deleted” flag instead of removing rows.
- Orphaned Data: Handling data that references a deleted user.
- Anonymization: Replacing personal identifiers with hashes.
Data Minimization
Only store data that is strictly necessary. Excessive metadata collection increases storage costs and privacy risks.
- Retention Policies: Automatic deletion of logs after a set period.
- Granular Permissions: Access controls at the row level.
- Encryption: Sensitive fields encrypted at rest.
Handling Metadata and Logs 📉
Beyond the core entities, systems generate vast amounts of metadata. This includes analytics, error logs, and audit trails. These should not clutter the main transactional schema.
Separation of Concerns
Keep the transactional database clean. Offload heavy logging and analytics to separate systems.
- Event Streams: Use message queues for asynchronous logging.
- Analytics Tables: Separate tables for historical trends.
- Time-Series Data: Specific storage for metrics over time.
Iterative Design Process 🔄
ERDs are rarely perfect on the first draft. Social media requirements evolve rapidly as new features are introduced. The design process should be iterative.
- Prototype: Build a minimal viable schema for the core feature.
- Test: Load test with realistic data volumes.
- Refactor: Adjust relationships based on performance bottlenecks.
- Document: Maintain up-to-date diagrams for future developers.
Common Pitfalls to Avoid ⚠️
Even experienced architects make mistakes when modeling social data. Recognizing these patterns helps prevent future issues.
- Over-Indexing: Too many indexes slow down write operations significantly.
- Ignoring Timezones: Storing timestamps without timezone context leads to confusion.
- Hardcoded Values: Avoid embedding business logic in the schema (e.g., specific status values).
- Neglecting Soft Deletes: Hard deletes can break foreign key constraints across the network.
- Unbounded Growth: Failing to archive old data leads to table bloat.
Final Considerations for Future Growth 🔮
Building a social media platform is a long-term endeavor. The data model must be flexible enough to accommodate changes without requiring a complete rewrite. Focus on clarity, scalability, and maintainability. Regular reviews of the schema against real-world usage patterns ensure the system remains robust as it scales.
- Versioning: Plan for schema migrations that support backward compatibility.
- Monitoring: Track query performance to identify schema weaknesses early.
- Community Feedback: Listen to how data is actually used by the engineering team.
By adhering to these strategies, developers can create a solid foundation for user-centric applications. The ERD is not just a diagram; it is the structural integrity of the entire platform. Careful planning now prevents significant technical debt later.